Experimental triggerNextLedger timer Change#4865
Conversation
6af4b3f to
99cf3aa
Compare
99cf3aa to
24db760
Compare
24db760 to
52b7601
Compare
538021b to
72a3614
Compare
7a0d9bc to
226b1e7
Compare
226b1e7 to
fbbbdc4
Compare
785022c to
b17483d
Compare
Key findingsOverall, the change works as expected. When clocks are mostly synced and most nodes enable the new timer, We do see that nomination timeouts and nomination timing overall increase fairly significantly when clocks However, as clocks become unsynced, we do see a significant increase in timeouts and nomination timing. Importantly, while performance does decrease, the network does not get wedged, and degrades back to the We actually see the peak decrease in performance at around 6 seconds of absolute clock drift. This seems to I also tested with a mixed network, where some nodes did not have the flag enabled while others did. Block time gradually decreases This seems to indicate that this feature is fine as a non-protocol upgrade. Given that the network can proceed with Setup
The general idea is to try to mimic pubnet as close as possible, without spinning up hundreds of Changes to MetricsOur traditional ledger.age.current-seconds benchmark is not accurate in determining the actual network We've also added meta info to node names. pX and mY indicate the node has a drifting Test ResultsFirst, we want to analyze the change itself, where all nodes have the new timer change. We will then All the following results have the experimental timer disabled on the left, and then enabled on all nodes No Drifthttps://grafana.stellar-ops.com/goto/bGk5BZTDg?orgId=1 Block Time
We see a similar block time to pubnet in our control of 5.7s. With the experimental timer, this drops to 5.01 seconds. Nomination Timeouts
We see an increase in timeouts with the new timer. Nomination p75We see an increase in nomination timing with the timer change:
Compared to the control group:
Nomination p99We see an increase again with the timer change:
Compared to the control group:
2 Second Absolute DriftAll nodes given a random drift uniformly selected from [-1000,+1000] ms. https://grafana.stellar-ops.com/goto/ttwsLWTvg?orgId=1 Block Time
We see little change compared to synchronized clocks. Nomination Timeouts
Elevated nomination timeouts observed in both experimental and non-experimental runs. Nomination p75We see a significant increase in nomination time in the experimental timer, compared to
Compared to no experimental flags
Nomination p99
Compared to no experimental flags
6 Second Absolute DriftAll nodes given a random drift uniformly selected from [-3000,+3000] ms. https://grafana.stellar-ops.com/goto/3w0a6Kovg?orgId=1 Block TimeAt this point, we see higher variance in the experimental timer and slower blocks overall, but still faster than
Nomination TimeoutsWe see a significant increase in timeouts compared to more synced clocks.
Nomination p75Much higher nomination times as well, with the new timer:
Compared to control:
Nomination p99
Experimental Timer:
Compared to control:
20 Second Absolute DriftAll nodes given a random drift uniformly selected from [-10,+10] seconds. At this point, https://grafana.stellar-ops.com/goto/I05-W5ovg?orgId=1 Block TimeBasically the same as the control block time with relatively low variance.
Nomination TimeoutsStill significantly greater than the control, but less than the 6 second absolute drift case.
Nomination p75Still larger than the control, but much improved from the 6 second case. With trigger timer:
vs baseline:
Nomination p99
vs baseline:
Extreme bimodal distributionOriginally what I expected to be a worst case stress test. 25% of nodes with minor drift (within 1 second), My laptop died between runs, so they are on separate graphs. Baseline, Block TimeFunctionally equivalent. Experimental timer:
Baseline:
Nomination TimeoutsExperimental timer:
Baseline:
Nomination p75Experimental:
Baseline:
Nomination p99Experimental:
Baseline:
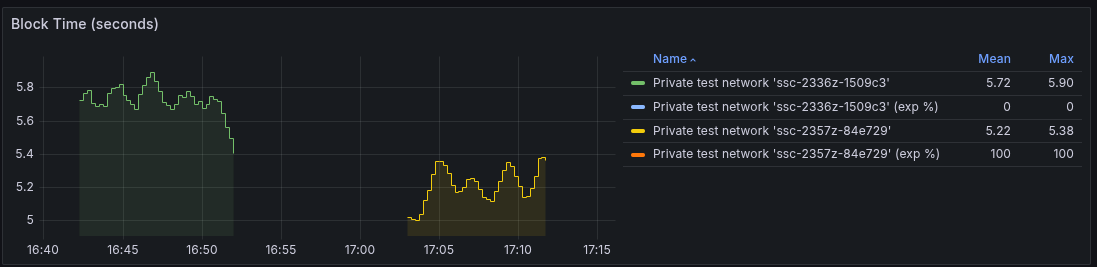
Network with mix of experimental flag and non-experimental flagFor this test, we used a moderate clock drift of +- 1 second across all nodes. We then ran several This grafana board shows several Block TimeWe see blocktime decrease gradually as more timers are enabled, but with higher variance in mixed networks. At around
NominationWhenever a node enables the experimental flag, it's nomination timeouts and timing increase based on how much of the During this in-between phase, only nodes with the new timer seem affected. Even when most of the nodes have upgraded their Timeouts
Nomination Timing
Different topologiesMost testing was with topology 1, as this is the "closest" 100 node approximation to pubnet, where tier 1 is moderately While other tests were run at 250 TPS, both the control and experimental flag failed at this load, so we reduced to 150 TPS. Worst case topology, no drifthttps://grafana.stellar-ops.com/goto/U5eoCpTvg?orgId=1 We tested the worst case topology with "realistic" ntp drift (+- 100ms).
Nomination timeouts and timing were increased, more so than in topology
Worst case topology, worst case driftWith topology 3 and the worst drift of 6 seconds absolute, we see high https://grafana.stellar-ops.com/goto/ja6WR2oDg?orgId=1 Max TPSWhile not the primary motivation of this change, the max TPS test gives us some It looks like the experimental timer has a small increase in overall max tps, Here is the max TPS test with the experimental timer |






























There was a problem hiding this comment.
Pull request overview
Adds an experimental mode to anchor HerderImpl’s triggerNextLedger scheduling off the last externalized SCP close time (with drift/availability fallbacks), plus test-only knobs to simulate clock drift and slow nomination message emission.
Changes:
- Add
EXPERIMENTAL_TRIGGER_TIMERand implement consensus-close-time-based trigger anchoring with fallback/metrics. - Add test-only support for simulated system clock drift and delayed nomination emit to exercise timeout/drift behavior.
- Add a new SCP trigger fallback meter and a (hidden) herder simulation test covering drift and long nomination scenarios.
Reviewed changes
Copilot reviewed 15 out of 15 changed files in this pull request and generated 5 comments.
Show a summary per file
| File | Description |
|---|---|
| src/util/Timer.h | Adds test-only system clock offset state + new actual_and_fake_system_now() API. |
| src/util/Timer.cpp | Implements drifted system_now() via injected offset and exposes paired sampling helper. |
| src/test/test.cpp | Enables the experimental trigger timer in the default test config. |
| src/scp/Slot.h | Adds a test-only SCP timer ID for delayed nomination emission. |
| src/scp/SCPDriver.h | Adds a test-only virtual hook for configuring nomination emit delay. |
| src/scp/NominationProtocol.cpp | Defers nomination broadcast in tests via a new driver timer when configured. |
| src/main/Config.h | Adds EXPERIMENTAL_TRIGGER_TIMER and two new test-only timing knobs. |
| src/main/Config.cpp | Initializes/parses new config options; extends testing-only option list. |
| src/main/ApplicationImpl.cpp | Applies configured test-only system clock offset at startup via VirtualClock. |
| src/herder/test/HerderTests.cpp | Adds a (hidden) simulation test for experimental trigger behavior under drift/slow nomination. |
| src/herder/HerderSCPDriver.h | Declares test-only nomination emit delay accessor; exposes nomination timeout count getter. |
| src/herder/HerderSCPDriver.cpp | Implements test-only nomination emit delay accessor and special-cases emit timer callback behavior. |
| src/herder/HerderImpl.h | Declares new trigger anchor helper methods and adds a fallback meter to SCP metrics. |
| src/herder/HerderImpl.cpp | Implements consensus-close-time anchoring logic, fallback conditions, and new metrics wiring. |
| docs/metrics.md | Documents the new scp.trigger.prepare-start-fallback meter. |
| // Returns both the unshifted and drifted system time samples captured from | ||
| // the same underlying timestamp source. | ||
| std::pair<system_time_point, system_time_point> | ||
| actual_and_fake_system_now() const noexcept; |
There was a problem hiding this comment.
actual_and_fake_system_now() is added as a new public VirtualClock API, but it’s currently only used internally by system_now(). If it’s only needed for test drift injection, consider making it private (or #ifdef BUILD_TESTS) to avoid widening the public surface area of VirtualClock without a clear production use-case.
| REQUIRE(herder0.getSCP().getHighestKnownSlotIndex() < FAR_FUTURE_BASE); | ||
| } | ||
|
|
||
| TEST_CASE("experimental trigger timer", "[herder][hide]") |
There was a problem hiding this comment.
This new test is tagged [hide], which typically excludes it from default CI runs. If this is meant to validate the experimental trigger timer behavior going forward, consider making at least a small/fast subset non-hidden (or adding a non-hidden unit test) so regressions are caught automatically.
| TEST_CASE("experimental trigger timer", "[herder][hide]") | |
| TEST_CASE("experimental trigger timer", "[herder]") |
| auto const newTimer = runSimulation(true, nominationDelay); | ||
|
|
||
| REQUIRE(oldTimer.elapsed > newTimer.elapsed); | ||
| REQUIRE(newTimer.elapsed < oldTimer.elapsed); |
There was a problem hiding this comment.
These two assertions are equivalent (oldTimer.elapsed > newTimer.elapsed and newTimer.elapsed < oldTimer.elapsed). Consider keeping just one to reduce redundancy.
| REQUIRE(newTimer.elapsed < oldTimer.elapsed); |
| "ARTIFICIALLY_SLEEP_MAIN_THREAD_FOR_TESTING", | ||
| "ARTIFICIALLY_DELAY_NOMINATION_EMIT_FOR_TESTING", | ||
| "ARTIFICIALLY_SKIP_CONNECTION_ADJUSTMENT_FOR_TESTING", | ||
| "ARTIFICIALLY_DELAY_LEDGER_CLOSE_FOR_TESTING", | ||
| "SKIP_HIGH_CRITICAL_VALIDATOR_CHECKS_FOR_TESTING", |
There was a problem hiding this comment.
ARTIFICIALLY_SET_SYSTEM_CLOCK_OFFSET_FOR_TESTING is parsed (under BUILD_TESTS) but isn’t listed in TESTING_ONLY_OPTIONS, so it won’t get the standard “testing-only option” warning logged when present. Consider adding it to TESTING_ONLY_OPTIONS for consistency with the other ARTIFICIALLY_*_FOR_TESTING knobs.
There seems to be a consistent increase in nomination time and timeouts across different measurements with the timer change. How can we reason about those? That doesn't seem expected, does it? |
| // Compute the anchor for the next trigger. Caller fires at | ||
| // `anchor + expectedClose`. Unlike the local ballot cadence trigger, this uses | ||
| // the externalized close time from the previous ledger, which is a timestamp | ||
| // coming from a different, potentially unsynced node. This is more accurate |
There was a problem hiding this comment.
unsynced can be a little confusing here - could you specify that it means nodes with drifted clock?
| // leader, but we need to be careful to account for drift. | ||
| // | ||
| // Constraints: | ||
| // 1. Track `expectedClose` on the network timeline as closely as possible. |
There was a problem hiding this comment.
I might be missing context here, but can you elaborate on the reasoning here please? Not sure I understand constraints (2) and (3). Why are longer blocks a preferred heuristic? For (3), I'm not actually sure this is possible.
Based on my tests, I see two different classes of increase: a small increase when clocks are synced, and a much larger increase under drifting clocks. In the first case (see no drift above), I think the increase is more of an artifact of decreased block time. We've shaved 700 ms off of block time, which means we have less buffer for slow nodes. With the old timer, because we started blocks late, we have more time for slow nodes to catch up before starting nomination. We tested at a fairly high TPS for this topology/pod config, so nodes were stressed. In addition to faster blocks, high latency nodes are much more likely to have more timeouts/higher nomination times because they trigger faster. Suppose we have a node N whose blocking set has latency L relative to each other, but N has latency 2L with its blocking set. Previously, node N starts nomination about L time behind the rest of it's blocking set. This is because the current timer is based on local ballot state. N will take 2L time to get the messages required to enter this phase, while the rest of the blocking set only takes L time. The nomination time of N appears smaller, since it started the timer later. With this change, all nodes start the block timer at the same time, regardless of latency. This results in N starting nomination faster, but actually taking more time to complete nomination since it still has 2L latency with it's peers. The second case, where clocks are not synced, shows much larger nomination changes. I think this is because some nodes start nomination so early/so late that it's impossible to make progress in that round. For example, suppose a single node is 2 seconds ahead of it's blocking set. That node will have up to 2 whole seconds of attempting nomination where none of it's quorum has begun nomination. Wrt the second case, my main priority is to ensure that the network remains relatively live in this scenario. Synchronized clocks are an assumption of basically every performance orientated L1 these days, and most node operator instructions include instructions for running NTP sync (which we need to give to tier 1). We should also warn more aggressively when clocks are out of sync to encourage good clock behavior from tier 1s. I don't think we should expect the network to maintain performance is this case (we can't), but we need to make sure that we don't overload or snowball the network via timeout load and are resistant to byzantine or incompetent validators. |
|
based on your findings above, would it make sense to first land the work around fully connected tier-1 that will place all validators within at most 2 hops? |
It would definitely decrease nomination load with this change. One test I'm curious about though is if the nomination changes are more attributable to the timer change or the blocktime change. For desynced clocks, it's definitely caused by the timer. For in-sync or lightly desynced clocks, I wonder if it's more the timer or blocktime. I can run a test where I lower the target blocktime on the control timer to around 4.2s so we can try to get an average around 5 seconds to compare. All that to say, the network will definitely perform better with the trigger timer + topology change, but I don't know if we're blocked on the topology change or not. I think it's likely we see increased nomination timeouts with this change regardless, given that we are increasing the TPS by ~15%. We definitely need to get clocks synced before rollout, but let me run a few more tests wrt topology. The relevant questions seem to be:
|
b17483d to
bc66a97
Compare
Description
This adds an experimental flag that when set, uses the closeTime from the last externalized SCP message as the basis for setting the triggerNextLedger timer.
I include a couple of basic unit tests, making sure that the behavior of the trigger is correct when nodes are drifting and when we have long nomination timeouts. Most of the simulation testing is reported below using this super cluster change: stellar/supercluster#384
Checklist
clang-formatv8.0.0 (viamake formator the Visual Studio extension)