

Make any AI model ~34% smaller with bit-identical weights — and let it decide how to run on your machine. Your machine runs bigger models than you think, and BigSmall never lies to you about it.
pip install bigsmall # CLI + compression/decompression
pip install bigsmall[torch] # add this for model loading (from_pretrained)A 14 GB Mistral-7B becomes 9.3 GB. A fine-tuned model becomes a 5 GB patch on top of its 14 GB base. A 14.2 GB model runs in ~2.5 GB of working memory through the streaming executor (it reads weights from disk layer by layer instead of holding the whole model). The decompressed model is every weight bit-for-bit identical to the original — each tensor's md5 (a checksum) is verified on decompress.
Three commands. No settings to learn.
bigsmall profile # once: ~10s hardware probe (saved, never asked again)
bigsmall plan model.bs # one sentence: what would run, where, how faithfully
bigsmall run model.bs # do itReal output from the reference machine (8-core CPU, RTX A4500 busy with another job):
$ bigsmall plan qwen2.5-0.5b.bsd
Running perfect mode (bit-exact, receipt verified) in CPU RAM at full CPU speed while the GPU is busy — fast mode (lossy INT4) available with --mode fast.
$ bigsmall run qwen2.5-0.5b.bsd
Running perfect mode (bit-exact, receipt verified) in CPU RAM at full CPU speed while the GPU is busy — fast mode (lossy INT4) available with --mode fast.
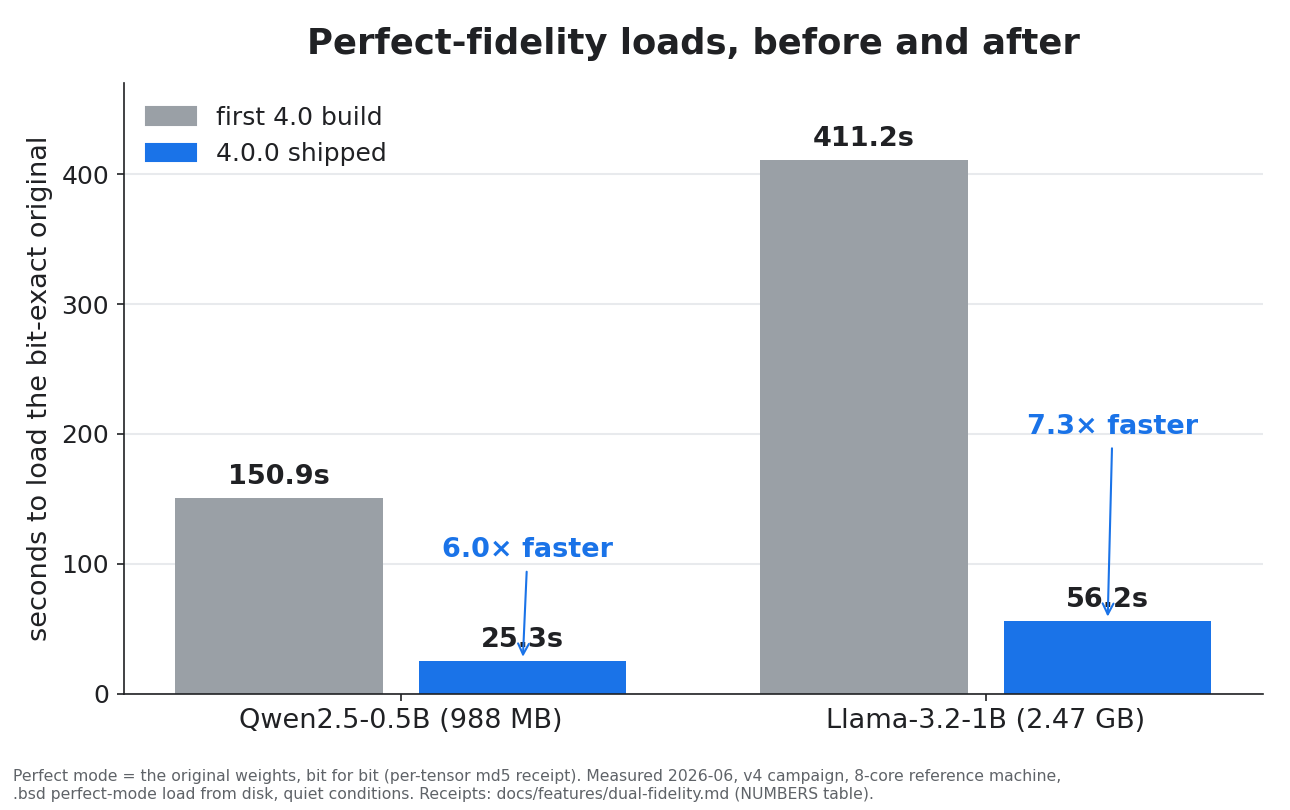
loaded 290 tensors into host RAM in 27.0s [mode=perfect] (bit-exact receipt honoured)
The planner picks the highest fidelity that runs at usable speed on your hardware, and one rule is enforced by the test suite itself: anything below bit-exact is announced before it happens, never silently. Full walkthrough: docs/quickstart.md.
| Feature | What you get | Command |
|---|---|---|
| Autopilot | No decisions: profile once, then one-sentence picks with receipts | bigsmall profile / plan / run — docs |
Ferrell Duo (.bsd) |
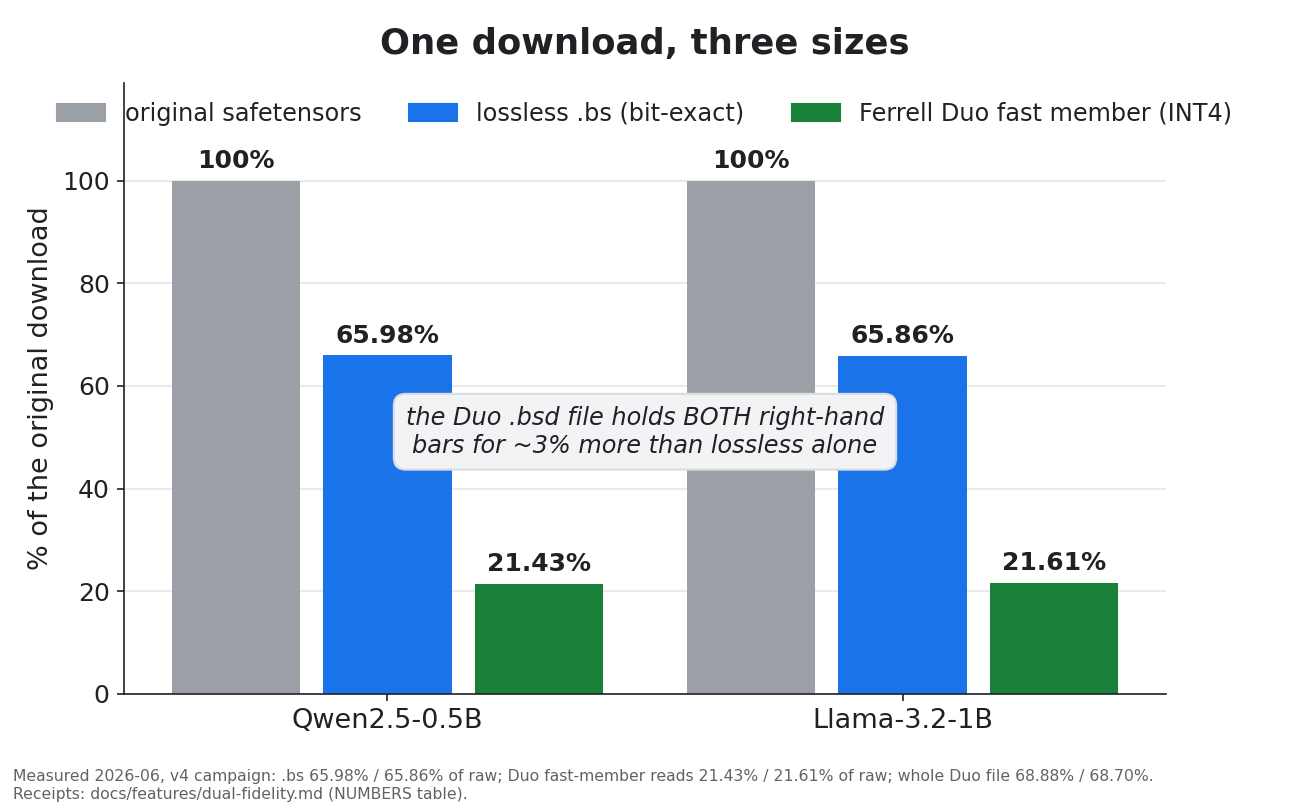
One file. Two models: the fast one (INT4, reads 21.4% of raw) and the real one (bit-exact, proven) — for ~2.9 pp over lossless-only | bigsmall dual — docs |
| Streaming executor | Run models bigger than your RAM: bounded resident set, promise checked against measurement every run | bigsmall run --stream, serve-stream — docs |
| FP8-native lossless | Models released in fp8 compress to 0.829 of their fp8 bytes, bit-exact | bigsmall compress (automatic) — docs |
| Capacity math | What fits on your card, computed honestly (13B-class lossless resident on a 20 GB GPU) | bigsmall plan — docs |
| Integrity tooling | Bit-exact receipts in the file, checkpoint forensics, an untrained-model trap | bigsmall xray, verify — docs |
Everything from 3.x is still here: delta patches for fine-tunes, KV-cache compression (entry v3 + FP8 + 32k chunked + GPU codec), xray, reshard, resume, ECC. Full changelog →
bigsmall compress mistral-7b/ -o mistral-7b.bs
bigsmall decompress mistral-7b.bs -o mistral-7b-restored/Before: 14.2 GB of safetensors. After: 9.3 GB .bs file. Saved: 4.9 GB (34%).
Every weight is bit-for-bit identical. Works on any safetensors model — LLMs, diffusion, audio, vision. BF16, F16, F32, and FP8 weights are all native.
bigsmall compress qwen-instruct/ --delta-from qwen-base/ -o instruct.bs
bigsmall apply qwen-base/ instruct.bs -o qwen-instruct-restored/Before: 14.2 GB Qwen2.5-7B-Instruct. After: ~5 GB patch. If your users already have the base model, they only download what changed. Delta size is pair-dependent — measured from under 1% of full size (best ≥7B SFT pairs) to ~61% (small-model full tunes); the ≥7B official-instruct class measures 34–50%. The engine measures both codings per tensor and never ships a delta larger than standalone. Full table: docs/delta-compression.md.
bigsmall dual qwen2.5-0.5b/model.safetensors -o qwen2.5-0.5b.bsd
bigsmall run qwen2.5-0.5b.bsd # perfect: bit-exact, verified
bigsmall run qwen2.5-0.5b.bsd --mode fast # fast: INT4, reads 21.4% of rawA .bsd is a Ferrell Duo: use the fast one while you work (a lossy-INT4 member that loads by reading a fifth of the bytes); the real one is the exact original — every bit, proven. The same file holds the lossless residual that reconstructs the original bits, receipt included. Measured cost: a .bsd is ~2.9 pp of raw larger than the lossless-only .bs (details).
bigsmall run model.bsd --streamThe layer-streaming executor keeps the resident set bounded and tells you the bound before it starts. Measured receipt, Qwen2.5-7B (14.2 GB raw): streamed forward pass bit-exact against the fully-loaded model (identical logits sha256) in ~2.5 GB of hot state. Slow is stated plainly where it is slow — see docs/features/streaming.md for the measured rates.
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"wpferrell/phi-3.5-mini-instruct-bigsmall"
)Works exactly like a normal HuggingFace model — BigSmall decompresses transparently on load. 25+ pre-compressed models ready to use (browse them all).
Every row is a real measurement. Click a model to download it.
| Model | Original | BigSmall | Saved |
|---|---|---|---|
| Qwen2.5-14B-Instruct | 29.5 GB | 19.5 GB | 34% |
| Gemma-3-12B-it | 22.7 GB | 14.8 GB | 35% |
| Gemma-2-9B-it | 17.2 GB | 11.3 GB | 34% |
| Llama-3.1-8B-Instruct | 15.0 GB | 9.7 GB | 35% |
| Llama-3-8B-Instruct | 15.0 GB | 9.8 GB | 34% |
| Qwen3-8B | 15.3 GB | 10.1 GB | 34% |
| Mistral-7B-Instruct v0.3 | 14.2 GB | 8.9 GB | 37% |
| Mistral-7B-Instruct v0.2 | 14.2 GB | 8.9 GB | 37% |
| Qwen2.5-7B-Instruct | 14.2 GB | 9.4 GB | 34% |
| Phi-3.5-mini-instruct | 7.1 GB | 4.7 GB | 34% |
| Gemma-3-4B-it | 8.0 GB | 5.2 GB | 35% |
| Qwen3-4B-Instruct | 7.5 GB | 5.0 GB | 34% |
| Llama-3.2-3B-Instruct | 6.4 GB | 3.9 GB | 39% |
| Gemma-2-2B-it | 4.9 GB | 3.2 GB | 34% |
| Qwen2.5-3B-Instruct | 5.7 GB | 3.8 GB | 34% |
| Qwen2.5-1.5B-Instruct | 2.9 GB | 1.9 GB | 34% |
| Llama-3.2-1B-Instruct | 2.3 GB | 1.5 GB | 34% |
| Gemma-3-1B-it | 1.9 GB | 1.2 GB | 35% |
| Qwen2.5-0.5B-Instruct | 920 MB | 610 MB | 34% |
| GPT-2 (117M) | 548 MB | 414 MB | 24% |
| Gemma-3-270M-it | 500 MB | 330 MB | 34% |
| Gemma-3-270M | 500 MB | 330 MB | 34% |
| Gemma-2-2B | 9.7 GB | 8.1 GB | 17% |
Browse all 25+ models on HuggingFace →
v4-line measurements on the reference machine (2026-06 campaign): Qwen2.5-7B compressed to 65.95% of raw and ran bit-exact through the streaming executor; a real fp8 release (Qwen3-0.6B-FP8) compressed to 0.829 of its fp8 weight bytes, 507/507 tensors bit-exact.
Every weight in the model is mathematically identical to the original — same bit pattern, same floating-point value, same gradient, same output.
- Not quantization. Quantization rounds weights to fewer bits and the model's behaviour changes. (The
.bsdfast member is quantization — and is labelled lossy every time it is picked, which is the point.) - Not pruning. Pruning deletes weights.
- Not approximation. No tricks, no calibration data, no quality drop.
BigSmall finds redundancy in the bit pattern of neural weights and stores it more compactly — the same idea as ZIP for text, but tuned for BF16 floating-point distributions. md5 is verified on every tensor at decompression. If a single bit differs, verify fails.
The honesty rules are code, not policy: any pick below a file's best fidelity carries a mandatory announcement, the announcement is printed before the load, and a test sweep across every profile × file × override combination fails the suite if a downgrade could ever happen silently. Details: docs/features/integrity.md.
bigsmall profile one-time hardware probe (~10s)
bigsmall plan SRC [--mode M] the decision, one sentence, no execution
bigsmall run SRC [--mode M] [--stream] pick, announce, load (or stream)
bigsmall dual SRC [-o OUT.bsd] create/inspect a dual-fidelity .bsd
bigsmall compress SRC [-o OUT] [--delta-from BASE] [--resume] [--ecc]
bigsmall decompress SRC [-o OUT] [--base BASE]
bigsmall transcode SRC DST.bsr [--mode M] re-encode for decode speed
bigsmall serve-stream SRC [--prompt ...] tiered weight-streaming inference
bigsmall xray SRC checkpoint forensics
bigsmall info | scan | stat | verify | diff | apply | repair | benchmark
bigsmall migrate | status | pipeline run | reshard
Every command has --help. See docs/cli-reference.md for full examples with real output.
import bigsmall
# Round-trip a model
bigsmall.compress("model/", "model.bs")
bigsmall.decompress("model.bs", "model_back/")
# Fine-tune as a delta patch
bigsmall.compress("finetune/", "patch.bs", delta_from="base/")
bigsmall.apply("base/", "patch.bs", "finetune_back/")
# Inspect before compressing
bigsmall.detect_bf16_native("model/")
bigsmall.scan_model("model/")
# Low-VRAM streaming inference (~12x less VRAM than from_pretrained)
from bigsmall import BigSmallStreamingModel
model = BigSmallStreamingModel.from_pretrained(
"wpferrell/phi-3.5-mini-instruct-bigsmall",
device="cuda",
lru_max_vram_gb=2.0,
)
# Stream-decompress straight from the HF CDN — no .bs written to disk
state_dict = bigsmall.stream_from_hub("wpferrell/gpt2-bigsmall", device="cpu")
# Reshard .bs files along layer boundaries, no re-encoding
bigsmall.reshard(["model.bs"], "resharded/", target_shard_size_gb=2.0)The lossless compression ceiling for BF16 neural weights has been measured. It is ~62% of raw BF16 for any model, ~34% for ≥7B instruct fine-tunes with delta compression. We ran 300+ experiments across every known mathematical approach — entropy coding, cross-tensor prediction, learned translators, persistent homology, optimal transport, quantum-inspired methods, and more — and proved that there is no further compression available within the strict bit-identity contract.
The floor is measured at the wall, not extrapolated: across 4,143 weight matrices in 8 architectures the per-tensor entropy floor is flat (coefficient of variation ≈ 0), and trained mantissa/sign bits are coder-equivalent to matched random controls in every family tested — training only writes the exponent. The floor exists at initialization and never moves during training. Details: docs/research.md.
Curious how BigSmall relates to DFloat11, ZipNN, GGUF quants, and the rest of the landscape? One honest reference page: docs/comparison.md.
The Ferrell Duo format has its own paper — how carrying the bit-exact original next to an INT4 fast member went from +13.4 to +2.9 points of file size, every number receipted: 10.5281/zenodo.20673133 (markdown, plain-English page).
Full findings, all experiments, all dead-ends: 10.5281/zenodo.20279247. Plain-English summary: docs/research.md.
pip install bigsmall # core
pip install "bigsmall[hf]" # + HuggingFace integration
pip install "bigsmall[ecc]" # + Reed-Solomon error recovery
pip install "bigsmall[all]" # everythingRequires Python 3.9+. Works on Linux, macOS, and Windows. CPU, NVIDIA, AMD, and Apple Silicon.
New here? Start with docs/quickstart.md, or find your situation in docs/how-it-helps.md.
Code: Elastic License 2.0. Free for personal, research, and commercial use. SaaS providers should see LICENSING.md.
Model weights distributed in .bs format keep the license of the original model.
- PyPI — https://pypi.org/project/bigsmall/
- GitHub — https://github.com/wpferrell/Bigsmall
- HuggingFace — https://huggingface.co/wpferrell
- Paper / DOI — https://doi.org/10.5281/zenodo.20279247 (always resolves to the latest version)
- Paper (PDF) — https://github.com/wpferrell/Bigsmall/blob/main/paper.pdf
- Docs — docs/
- Changelog — CHANGELOG.md
- Contact — wpferrell@gmail.com
Did BigSmall work for your model? We'd love to know.
- Open a Discussion — share your compression results, ask questions, or suggest improvements
- File an Issue — if something didn't work, tell us exactly what happened
- HuggingFace — all compressed models are at huggingface.co/wpferrell
We especially want to hear:
- Which model you compressed and what ratio you got
- Any errors or unexpected behaviour
- Use cases we haven't thought of